All in One View
Content from What is a HPC?
Last updated on 2023-05-16 | Edit this page
Estimated time: 15 minutes
Overview
Questions
- Why would I be interested in High Performance Computing (HPC)?
Objectives
- Describe what an HPC system is
- Identify how an HPC system could benefit you.
Introduction
Open the Introduction Slides in a new tab for an introduction to the course and Research Computing.
Defining common terms
What is cluster computing?
Cluster computing refers to two or more computers that are networked together to provide solutions as required.
A cluster of computers joins computational powers of the individual computers (called “compute nodes”) to provide a more combined computational power.
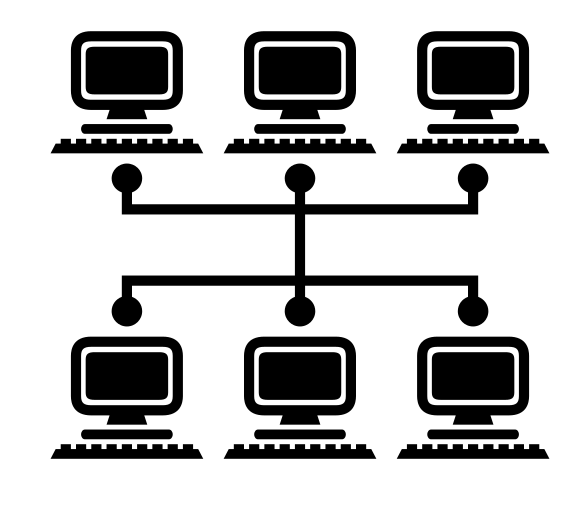
What is a HPC cluster?
HPC stands for High Performance Computing, which is the ability to process data and perform complex calculations at high speeds.
In its simplest structure, HPC clusters are intended to utilize parallel processors to apply more computing force to solve a problem. HPC clusters are a kind of compute clusters that typically have a large number of compute nodes, which share a file system designed for parallel reading and writing, and use a high-speed network for communication with each other.
What is a supercomputer?
Supercomputer used to refer to any single computer system that has exceptional processing power for its time. But recently, it refers to the best-known types of HPC solutions. A supercomputer contains thousands of compute nodes that work together to complete one or more tasks in parallel.
supercomputers and
high-performance computers are often used
interchangeably.
How is supercomputing performance measured?
The most popular benchmark is the LINPACK benchmark which is used for the TOP500. The LINPACK benchmark reflect the performance of a dedicated system for solving a dense system of linear equations. It uses the number of floating point operations per second (FLOPS) as the metric. The GREEN500 ranking has also risen in popularity as it ranks HPC systems based on FLOPS per Watt of power (higher the better).
When to use a HPC cluster?
Frequently, research problems that use computing can outgrow the capabilities of the desktop or laptop computer where they started, such as the following examples
- A statistics student wants to cross-validate a model. This involves running the model 1000 times – but each run takes an hour. Running the model on a laptop will take over a month! In this research problem, final results are calculated after all 1000 models have run, but typically only one model is run at a time (in serial) on the laptop. Since each of the 1000 runs is independent of all others, and given enough computers, it’s theoretically possible to run them all at once (in parallel).
- A genomics researcher has been using small datasets of sequence data, but soon will be receiving a new type of sequencing data that is 10 times as large. It’s already challenging to open the datasets on a computer – analyzing these larger datasets will probably crash it. In this research problem, the calculations required might be impossible to parallelize, but a computer with more memory would be required to analyze the much larger future data set.
In these cases, access to more (and larger) computers is needed. Those computers should be usable at the same time, solving many researchers’ problems in parallel.
Therefore, HPCs are userful when you have:
- A program that can be recompiled or reconfigured to use optimized numerical libraries that are available on HPC systems but not on your own system;
- You have a parallel problem, e.g. you have a single application that needs to be rerun many times with different parameters;
- You have an application that has already been designed with parallelism;
- To make use of the large memory available;
- When solutions require backups for future use. HPC facilities are reliable and regularly backed up.
How to interact with HPC clusters?
Researchers usually interact with HPC clusters by connecting remotely to the HPC cluster via the Linux command line. This is because of its low cost and setup as well as most research HPC software being written for the Linux command line. Microsoft Windows HPC facilities exist, but usually serve specific niches like corporate finance.
However, graphical interfaces have become popular and have helped lower the barrier to learning how to use HPC. Open OnDemand being the most popular example of software that helps users interact with HPC graphically.
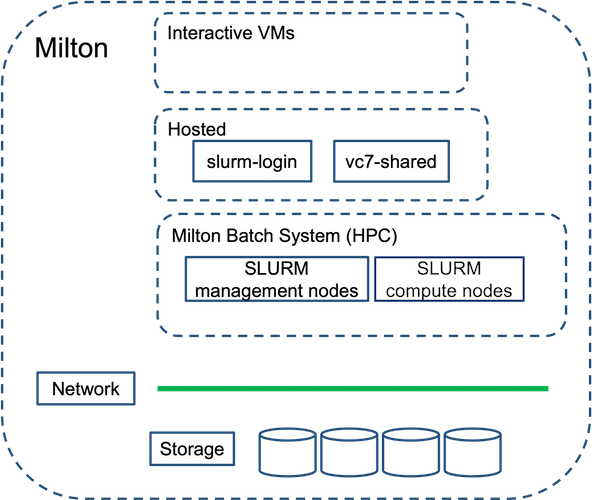
What is Milton?

In 2016, WEHI purchased an on-premise HPC cluster called Milton, Milton includes >4500-cores (2 hyperthreads per core), >60TB memory, ~ 58 GPUs, >10 petabytes of tiered-storage. All details are available here.
Milton contains a mix of Skylake, Broadwell, Icelake and Cooperlake Intel processors.
- Using High Performance Computing (HPC) typically involves connecting to very large computing systems that provides a high computational power.
- These systems can be used to do work that would either be impossible or much slower on smaller systems.
- HPC resources are shared by multiple users.
- The resources found on independent compute nodes can vary in volume and type (amount of RAM, processor architecture, availability of shared filesystems, etc.).
- The standard method of interacting with HPC systems is via a command line interface.
Content from Accessing Milton
Last updated on 2025-09-03 | Edit this page
Estimated time: 21 minutes
Overview
Questions
- How do I log in to
Milton? - Where can I store my data?
Objectives
- Connect to
Milton. - Identify where to save your data
Milton Cluster
Milton is a linux-based cluster, that is made up of two login nodes and many computer nodes in addition to the file systems.
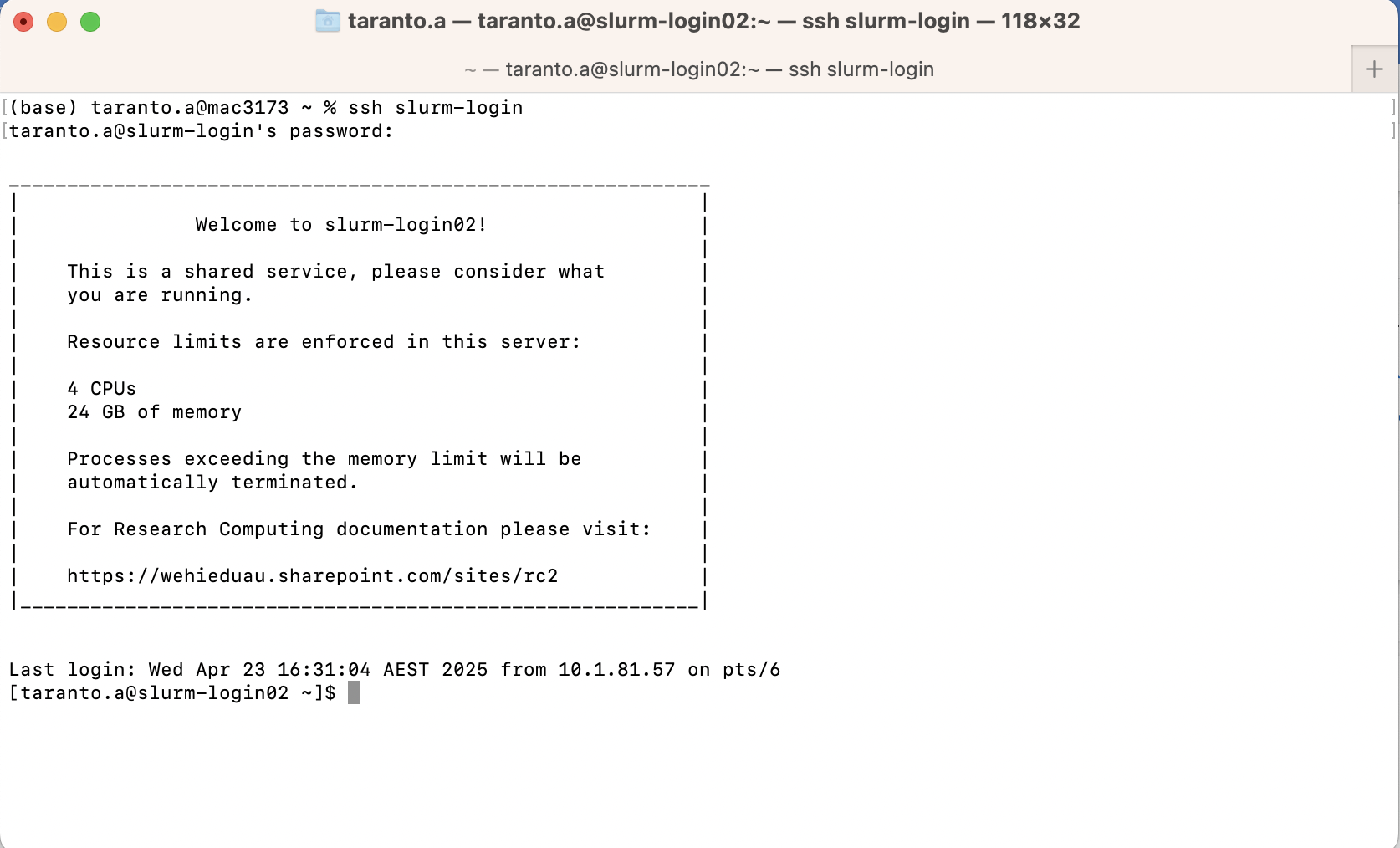
Connect to Milton
The first step in using a cluster is to establish a connection from your laptop to the cluster. You need a Windows Command Prompt or macOS Terminal, to connect to a login node and access the command line interface (CLI).
Exercise 1: Can you login to Milton?
If not in WEHI, make sure you are on the VPN. While on a WEHI device, open your terminal and login to slurm-login.
More details are available here.
- For Mac OSX users
ssh slurm-login- Type your password
- For MS-Windows users
- Download and install the free GitBash app.
- You can also use Cluster Access on Open OnDemand
You will be asked for your password.
Watch out: the characters you type after the
password prompt are not displayed on the screen. Normal output will
resume once you press Enter.
You will notice that the prompt changed when you logged into the remote system using the terminal.
Milton File Systems
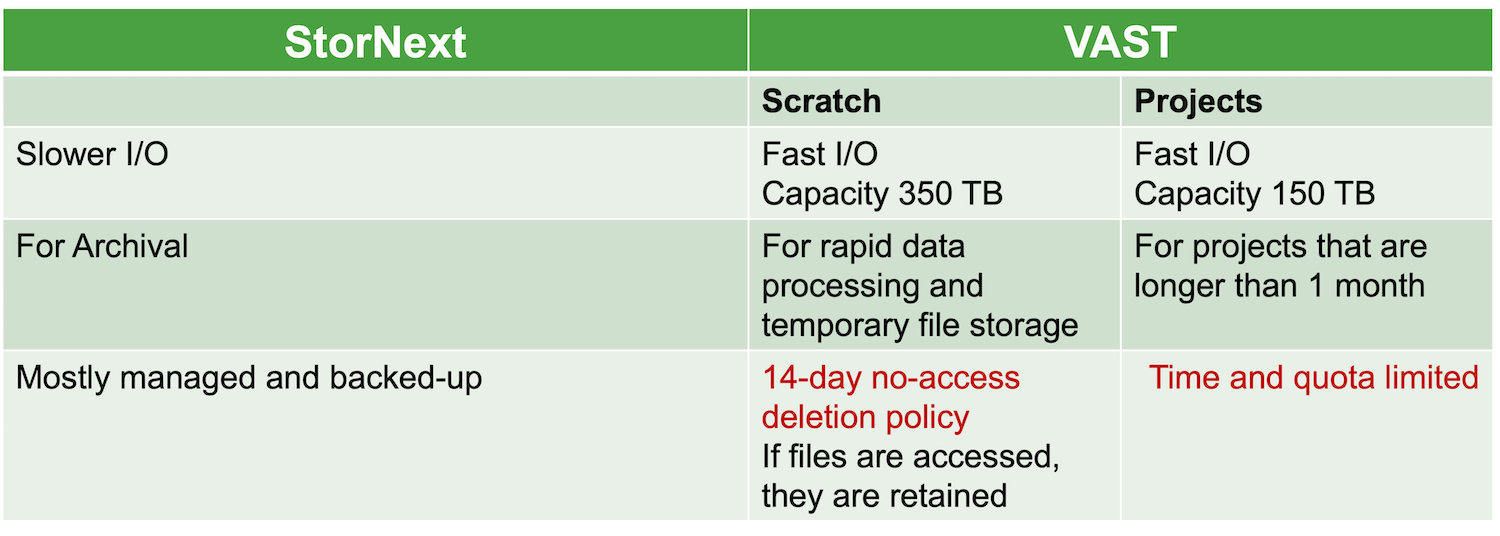
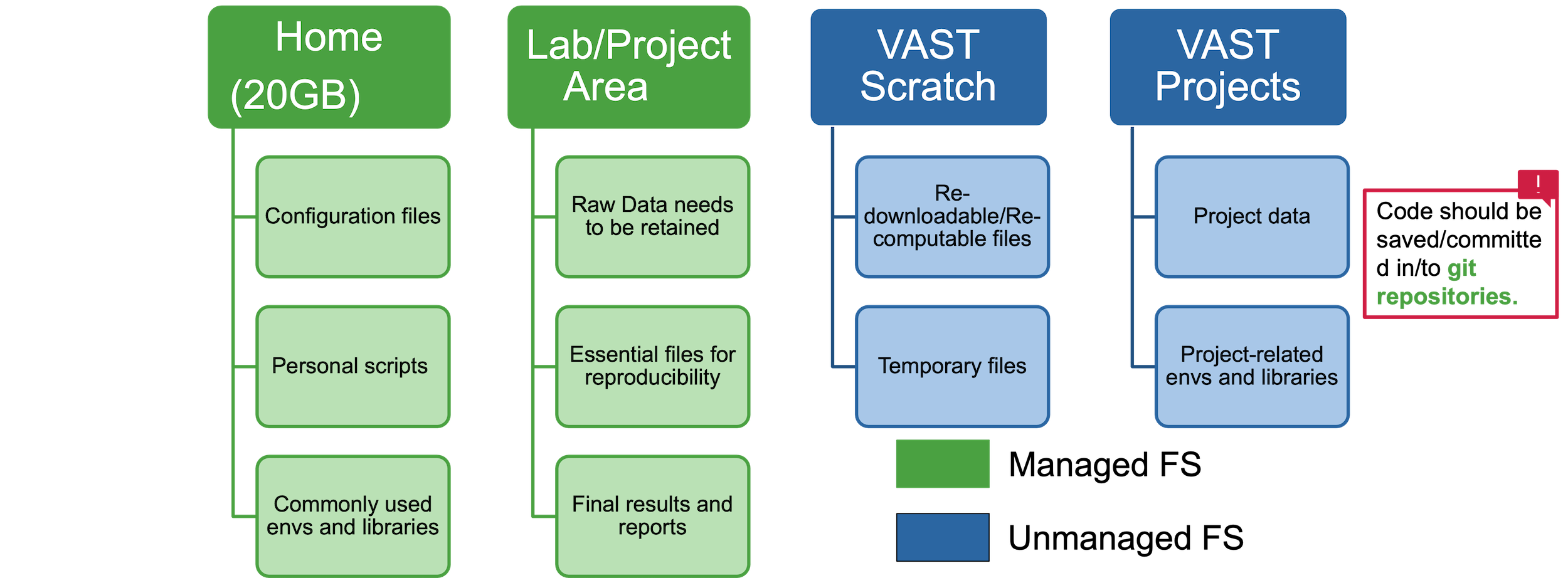
How data should be moved between file systems according to project requirements?
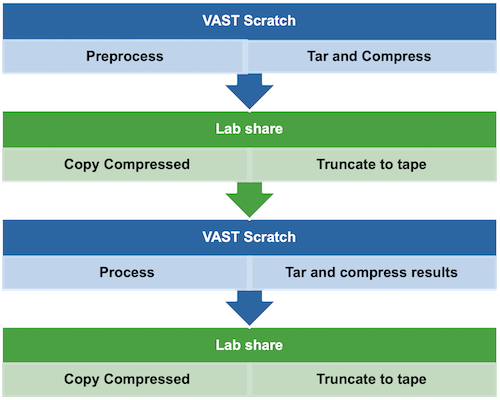
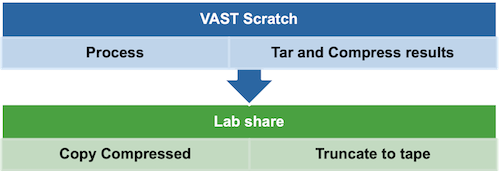
Check your available storage
Use module av to search for and load the
stornext module. Load it and run the mrquota
tool to view your available storage.
Check your available storage (continued)
Looks like my home dir is nearly full!
Looking Around Your Home
We will now revise some linux commands to look around the login node.
Exercise 2:Check the name of the current node
Get node name where you are logged into
Exercise 3: Find out which directory we are in.
Exercise 4: List all files and folders in your Home directory
Exercise 5: Copy Exercise examples to your vast scratch or home directory
Copy exercise examples from Github to current directory,
Exercise 6: Disconnect your session
For more on Linux commands, visit our guide or watch the recording of the workshops here
- HPC systems typically provide login nodes and a set of compute nodes.
- Files saved on one node are available on all nodes.
- Milton has multiple different file systems that have different policies and characteristics.
- Throughout a research project, research data may move between file systems according to backup and retention requirements, and to improve performance.
Content from Environment Modules
Last updated on 2025-04-23 | Edit this page
Estimated time: 17 minutes
Overview
Questions
- How do we load and unload software packages?
Objectives
- Load and use a software package.
- Explain how the shell environment changes when the module mechanism loads or unloads packages.
On Milton, many softwares are installed but need to be loaded before you can run it.
Why do we need Environment Modules?
- software incompatibilities
- versioning
- dependencies
Software incompatibility is a major headache for programmers. Sometimes the presence (or absence) of a software package will break others that depend on it.
Two of the most famous examples are Python 2 and 3 and C compiler
versions. Python 3 famously provides a python command that
conflicts with that provided by Python 2. Software compiled against a
newer version of the C libraries and then used when they are not present
will result in errors.
Software versioning is another common issue. A team might depend on a certain package version for their research project - if the software version was to change (for instance, if a package was updated), it might affect their results. Having access to multiple software versions allow a set of researchers to prevent software versioning issues from affecting their results.
Dependencies are where a particular software package (or even a particular version) depends on having access to another software package (or even a particular version of another software package).
Environment modules are the solution to these problems. A module is a self-contained description of a software package – it contains the settings required to run a software package and, usually, encodes required dependencies on other software packages. HPC facilities will often have their own optimised versions of some software, so modules also make it easier to use these versions.
module command
The module command is used to interact with environment
modules. An additional subcommand is usually added to the command to
specify what you want to do. For a list of subcommands you can use
module -h or module help. As for all commands,
you can access the full help on the man pages with
man module.
Listing Available Modules
To see available software modules, use module avail:
OUTPUT
--------------------------------------------------------------- /stornext/System/data/modulefiles/rhel/9/base/bioinf ----------------------------------------------------------------
bcftools/1.19 canu/2.2 deeptools/3.5.5 gatk/4.6.0.0 IGV/2.18.0 nanopolish/0.14.0 plink/1.9 spaceranger/3.1.1 ucsc-tools/362
bcftools/1.20 cellranger-arc/2.0.2 diamond/2.1.10 gridss/2.13.2 MACS2/2.2.9.1 ncbi-blast/2.16.0 plink2/2.00 spaceranger/3.1.2 varscan/2.4.6
bcftools/1.21 cellranger/8.0.1 dorado/0.6.0 hisat2/2.2.1 MACS3/3.0.1 nf-core/2.14.1 salmon/1.10.2 sra-toolkit/3.1.0
bcl-convert/3.10.5 cellranger/9.0.0 dorado/0.7.3 homer/4.11 mageck/0.5.9.5 nix/fix samtools/1.19.2 STAR/2.7.11b
bcl2fastq/2.20.0.422 cellsnp-lite/1.2.3 dorado/0.9.0 homer/5.1 meme/5.5.6 nix/latest samtools/1.20 subread/2.0.6
bedtools/2.31.1 cutadapt/4.8 ensembl-vep/112 htslib/1.19.1 minimap2/2.28 picard-tools/3.1.1 samtools/1.21 trimgalore/0.6.10
bowtie2/2.5.3 cutadapt/4.9 fastqc/0.12.1 htslib/1.20 MMseqs2/16-747c6 picard-tools/3.2.0 seqmonk/1.48.1 trimmomatic/0.39
bwa/0.7.17 deeptools/3.5.1 gatk/4.2.5.0 htslib/1.21 MultiQC/1.24 picard-tools/3.3.0 spaceranger/2.1.1 ucsc-tools/331
--------------------------------------------------------------- /stornext/System/data/modulefiles/rhel/9/base/nvidia ----------------------------------------------------------------
CUDA/11.8 CUDA/12.1 CUDA/12.3 CUDA/12.4 cuDNN/8.9.7.29-11 cuDNN/8.9.7.29-12 nvtop/3.1.0 TensorRT/8.6.1.6-11 TensorRT/8.6.1.6-12
-------------------------------------------------------------- /stornext/System/data/modulefiles/rhel/9/base/structbio --------------------------------------------------------------
alphafold/2.3.2 AreTomo/3.0.0_CUDA12.1 CryoPROS/1.0 DESRES/2023-4 gromacs/2024.2_CUDA12.4 patchdock/1.3 relion/5.0_CUDA12.1
alphafold/3.0.0 autodock/4.2.6 cryosamba/1.0 dials/3.9.0 H5toXDS/1.1.0 phenix/1.21.2-5419 rosetta/3.14
alphafold/3.0.1 autoPROC/20240710 ctffind/4.1.14 dssp/4.4.11 haddock3/2024.10.0b7 PRosettaC/d53ed49 RoseTTAFold-All-Atom/1.3-nosignalp
AlphaLink/1.0 bsoft/2.1.3 ctffind/4.1.14-MKL EMAN2/2.99.47 IMOD/5.0.2 pyem/0.63 spIsoNet/1.0
Amber/24 ccp4/7.1 ctffind/5.0.5 EMReady/2.0 motioncor2/1.6.4_CUDA11.8 pymol/2.5.0 topaz/0.2.5a
AreTomo/1.1.2_CUDA11.8 ccp4/8.0 dalilite/5.0.1 EPU_Group_AFIS/0.3 motioncor2/1.6.4_CUDA12.1 pymol/3.0.0 warp/2.0.0
AreTomo/1.1.2_CUDA12.1 chimerax/1.9 dectris-neggia/1.2.0 FastFold/0.2.0 motioncor3/1.0.1_CUDA11.8 relion/4.0.1_CUDA12.1 XDS/20240630
AreTomo/1.3.4_CUDA11.8 crYOLO/1.9.9 deepEMhancer/0.16 gromacs/2024.2 motioncor3/1.0.1_CUDA12.1 relion/5.0-beta_CUDA12.1 xdsgui/20231229
---------------------------------------------------------------- /stornext/System/data/modulefiles/rhel/9/base/tools ----------------------------------------------------------------
7zip/24.08 evince/3.28.2 JAGS/4.3.2 nextflow/24.04.2 oras/1.2.0 R/4.1.3 squashfuse/0.5.0
apptainer/1.2.5 fftw/3.3.10 jobstats/1.0.0 nextflow/24.10.5 owncloud-client/5.3.1.14018 R/4.2.3 stornext/1.1
apptainer/1.2.5-compat flexiblas/3.4.2 julia/1.10.4 ninja/1.11.1 pandoc/3.2 R/4.3.3 tar/1.35
apptainer/1.3.3 gcc/14.2 jupyter/6.5.7 nmap/7.94 parallel/20240722 R/4.4.1 texlive/2023
apptainer/1.3.5 gcloud-sdk/496.0.0 jupyter/latest nodejs/20.16.0 pcre2/10.42 R/4.4.2 texlive/2024
awscli/2.3.1 gdal/3.9.0 libjpeg-turbo/3.0.2 omero-py/5.19.6 perl/5.40.0 R/4.5.0 turbovnc/3.1.1
blis/0.9.0-omp-intel geos/3.12.1 libpng/1.6.43 oneMKL/2024.0.0.49673 perl/5.40.0-threads R/flexiblas/4.3.3 uv/0.5.31
blis/0.9.0-pt-intel git/2.46.0 libtiff/4.6.0 openbabel/2.4.0 pgsql/15.1 R/flexiblas/4.4.1 uv/0.6.12
blis/0.9.0-serial-generic glpk/4.65 mariadb-connector-c/3.3.10 openBLAS/0.3.26-haswell pigz/2.8 R/flexiblas/4.4.2 vast-trino/420
blis/0.9.0-serial-intel glpk/5.0 mediaflux-data-mover/1.2.11 openBLAS/0.3.26-omp-haswell postgresql/16.4 R/flexiblas/4.5.0 virtualgl/3.1.1
boost/1.72.0 gnuplot/6.0.1 micromamba/latest openBLAS/0.3.26-pt-haswell proj/9.4.0 rc-tools/1.0 virtualgl/3.1.2
boost/1.79.0 go/1.13.15 miniconda3/latest openBLAS/0.3.26-serial protobuf-c/1.5.0 rclone/1.67.0 websockify/0.11.0
boost/1.84.0 go/1.21.6 miniwdl/1.12.1 openCV/4.10.0 protobuf/3.14.0 rsync/3.3.0 xdotool/3.20211022.1
bzip2/1.0.8 GraphicsMagick/1.3.45 netcdf/4.9.2 openjdk/18.0.2 protobuf/3.28.1 singularity/4.1.3 Xvfb/1.20.11
cairo/1.19.0 hdf5/1.12.3 nextflow-tw-agent/0.5.0 openjdk/21.0.2 python/3.11.8 singularity/4.1.5 xz/5.4.6
cmake/3.30.2 hdf5/1.14.4-3 nextflow-tw-cli/0.8.0 openjdk/22.0.2 python/3.12.4 snakemake/8.11.3 zlib/1.3.1
curl/8.6.0 icewm/3.6.0 nextflow/22.10.4 openmpi/4.1.6 python/3.13.0 spack/0.21.2
dua-cli/2.29.0 ImageMagick/7.1.1 nextflow/23.10.0 openssl/3.2.1 quarto/1.4.554 squashfs-tools/1.3.1 Listing Currently Loaded Modules
You can use the module list command to see which modules
you currently have loaded in your environment. If you have no modules
loaded, you will see a message telling you so
OUTPUT
No Modulefiles Currently Loaded.Loading and Unloading Software
To load a software module, use module load. In this
example we will use Python 3.
Initially, Python 3 is not loaded. We can test this by using the
which command. which looks for programs the
same way that Bash does, so we can use it to tell us where a particular
piece of software is stored.
OUTPUT
/usr/bin/python3OUTPUT
Python 3.9.21We can look at the available python modules on
Milton
OUTPUT
---------------------------------------------------------------- /stornext/System/data/modulefiles/rhel/9/base/tools ----------------------------------------------------------------
python/3.11.8 python/3.12.4 python/3.13.0 Now, we can load the python 3.11.8 command with
module load:
OUTPUT
Python 3.11.8Using module unload “un-loads” a module along with its
dependencies. If we wanted to unload everything at once, we could run
module purge (unloads everything).
Now, if you already have a Python module loaded, and you try to load a different version of Python 3, you will get an error.
OUTPUT
Loading python/3.12.4
ERROR: Module cannot be loaded due to a conflict.
HINT: Might try "module unload python" first.You will need to module switch to Python 3.12.4 instead
of module load.
OUTPUT
Currently Loaded Modulefiles:
1) python/3.12.4Exercise 1: What does
module whatis python do?
Print information of modulefile(s)
Exercise 2: What does
module show python do?
Show the changes loading the module does to your environment
OUTPUT
-------------------------------------------------------------------
/stornext/System/data/modulefiles/rhel/9/base/tools/python/3.11.8:
module-whatis {a widely used high-level, general-purpose, interpreted, dynamic programming language. (v3.11.8)}
conflict python
unsetenv PYTHONHOME
setenv PYTHON_INCLUDE_DIR /stornext/System/data/software/rhel/9/base/tools/python/3.11.8/include/python3.11
prepend-path PATH /stornext/System/data/software/rhel/9/base/tools/python/3.11.8/bin
prepend-path CPATH /stornext/System/data/software/rhel/9/base/tools/python/3.11.8/include/python3.11
prepend-path MANPATH :/stornext/System/data/software/rhel/9/base/tools/python/3.11.8/share/man
prepend-path LD_LIBRARY_PATH /stornext/System/data/software/rhel/9/base/tools/python/3.11.8/lib
-------------------------------------------------------------------What is $PATH?
$PATH is a special environment variable that controls
where a UNIX system looks for software. Specifically $PATH
is a list of directories (separated by :) that the OS
searches through for a command before giving up and telling us it can’t
find it. As with all environment variables we can print it out using
echo.
When we ran the module load command, it adds a directory
to the beginning of our $PATH. That is the way it “loads”
software and also loads required software dependencies. The module
loading process manipulates other special environment variables as well,
including variables that influence where the system looks for software
libraries, and sometimes variables which tell commercial software
packages where to find license servers.
The module command also restores these shell environment variables to their previous state when a module is unloaded.
Note
The login nodes are a shared resource. All users access a login node in order to check their files, submit jobs etc. If one or more users start to run computationally or I/O intensive tasks on the login node (such as forwarding of graphics, copying large files, running multicore jobs), then that will make operations difficult for everyone.
- Load software with
module load softwareName. - Unload software with
module unloadormodule purge. - The module system handles software versioning and package conflicts for you automatically.
Content from Introducing Slurm
Last updated on 2025-04-24 | Edit this page
Estimated time: 20 minutes
Overview
Questions
- What is a scheduler and why does a cluster need one?
- What is a partition?
Objectives
- Explain what is a scheduler
- Explain how Milton’s Slurm works
- Identify the essential options to set for a job
Job Scheduler
An HPC system might have thousands of nodes and thousands of users. A scheduler is a special piece of software that decides which jobs run where and when. It also ensures that a task is run with the resources it requested.
The following illustration compares these tasks of a job scheduler to a waiter in a restaurant. If you can relate to an instance where you had to wait for a while in a queue to get in to a popular restaurant, then you may now understand why sometimes your job do not start instantly as in your laptop.

Milton uses a scheduler (batch system) called Slurm. WEHI has 3500 physical cores, 44TB of memory, 58 GPUs and 90 nodes accessible by Slurm.
The user describes the work to be done and resources required in a script or at the command line, then submits the script to the batch system. The work is scheduled when resources are available and consistent with policy set by administrators.
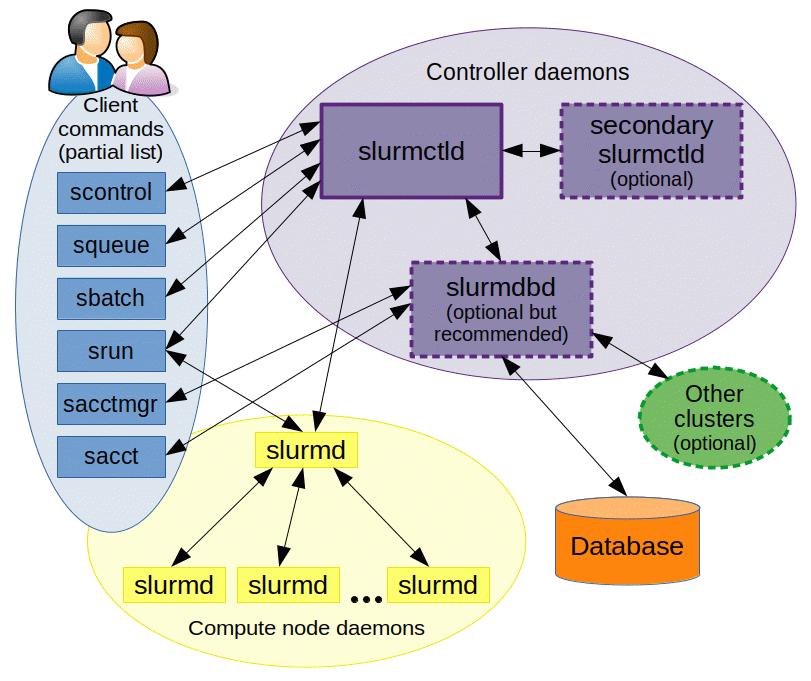
Slurm
Simple Linux Utility for Resource Management
Slurm development has been a joint effort of many companies and organizations around the world. Over 200 individuals have contributed to Slurm. Its development is lead by SchedMD. Its staff of developers and support personnel maintain the canonical Slurm releases, and are responsible for the majority of the development work for each new Slurm release. Slurm’s design is very modular with about 100 optional plugins. It is used at Spartan, Massive, Pawsey, Peter Mac and Milton, as well as HPC facilities world-wide.
Fair Share
A cluster is a shared environment and when there is more work than resources available, there needs to be a mechanism to resolve contention. Policies ensure that everyone has a “fair share” of the resources.
Milton uses a multifactor job priority policy. It uses nine factors that influence job priority.
It is set such that:
- age: as the length of time a job has been waiting in the queue increases, the job priority increases.
- job size: the more resources (CPUs, GPUs, and/or memory), the higher priority.
- fair-share: the difference between the portion of the computing resource that has been requested and the amount of resources that has been consumed, i.e. the more resources your jobs have already used, the lower the priority of your next jobs.
In addition, no single user can have more than 8% of total CPUs or memory, which is 450 CPUs and 3TB memory.
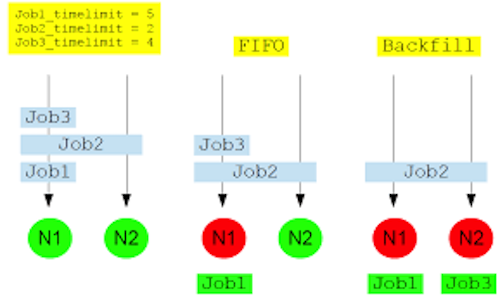
Backfilling
Milton uses a back-filling algorithm to improve system utilisation and maximise job throughput.
When more resource intensive jobs are running it is possible that gaps ends up in the resource allocation. To fill these gaps a best effort is made for low-resource jobs to slot into these spaces.
For example, on an 8-core node, an 8 core job is running, a 4 core job is launched, then an 8 core job, then another 4 core job. The two 4 core jobs will run before the second 8 core job.
if we have 2 8-core nodes, we receive:
- Job 1 request 4-cores and 5 hours limit
- Job 2 request 8-cores and 2 hours limit
- Job 3 request 4-cores and 4 hours limit
Without back filling, Job 2 will block the queue and Job 3 will have to wait until Job 2 is completed. With back filling, when Job 1 has been allocated and Job 2 pending for resources, Slurm will look through the queue, searching for jobs that are small enough to fill the idle node. In this example, this means that Job 3 will start before Job 2 to “back-fill” the 4 CPUs that will be available for 5 hours while Job 1 is running.
Slurm Partitions
Partitions in Slurm group nodes into logical (possibly overlapping) sets. A partition configuration defines job limits or access controls for a group of nodes. Slurm allocates resources to jobs within the selected partition by taking into consideration the resources you request for your job and the partition’s available resources and restrictions.
| Partition | Purpose | Max submitted jobs/user | Max CPUs/user | Max mem (GB)/user | Max wall time/job | Max GPUs/user |
|---|---|---|---|---|---|---|
| interactive | interactive jobs | 1 | 16 | 64 | 24 hours | 0 |
| regular | most of the batch work | 5000 | 454 | 3000 | 48 hours | 0 |
| long | long-running jobs | 96 | 500 | 14-days | 0 | |
| gpuq | jobs that require GPUs | 192 | 1000 | 48 hours | 8 A30 GPUs and 1 A100 GPU on 2 nodes | |
| bigmem | jobs that require large amounts of memory | 500 | 128 | 1400 | 48 hours | 0 |
The main parameters to set for any job script
- time: the maximum time for the job execution.
- cpus: number of CPUs
- partition: the partition in which your job is placed
- memory: the amount of physical memory
- special resources such as GPUs.
We will discuss this more in the next episode.
- The scheduler handles how compute resources are shared between users.
- A job is just a shell script.
- Request slightly more resources than you will need.
- Backfilling improves system utilisation and maximises job throughput. You can take advantage of backfilling by requesting only what you need.
- Milton Slurm has multiple partitions with different specification that fit the different types of jobs.
Content from Submitting a Job
Last updated on 2025-11-27 | Edit this page
Estimated time: 47 minutes
Overview
Questions
- How do I launch a program to run on a compute node in the cluster?
- How do I capture the output of a program that is run on a node in the cluster?
- How do I change resource requested or time-limit
Objectives
- Submit a simple script to the cluster.
- Monitor the execution of jobs using command line tools.
- Inspect the output and error files of your jobs.
Running a Batch Job
The most basic use of the scheduler is to run a command non-interactively. Any command (or series of commands) that you want to run on the cluster is called a job, and the process of using a scheduler to run the job is called batch job submission.
Basic steps are:
- Develop a submission script, a text file of commands, to perform the work
- Submit the script to the batch system with enough resource specification
- Monitor your jobs
- Check script and command output
- Evaluate your job
In this episode, we will focus on the first 4 steps.
Preparing a job script
In this case, the job we want to run is a shell script – essentially a text file containing a list of Linux commands to be executed in a sequential manner.
Our first shell script will have three parts:
- On the very first line, add
#!/bin/bash. The#!(pronounced “hash-bang” or “shebang”) tells the computer what program is meant to process the contents of this file. In this case, we are telling it that the commands that follow are written for the command-line shell. - Anywhere below the first line, we’ll add an
echocommand with a friendly greeting. When run, the shell script will print whatever comes afterechoin the terminal.-
echo -nwill print everything that follows, without ending the line by printing the new-line character.
-
- On the last line, we’ll invoke the
hostnamecommand, which will print the name of the machine the script is run on.
Exercise 1: Run example-job.sh
Run the script. Does it execute on the cluster or just our login node?
This script ran on the login node, but we want to take advantage of
the compute nodes, we need the scheduler to queue up
example-job.sh to run on a compute node.
Submit a batch job
To submit this task to the scheduler, we use the sbatch
command. This creates a job which will run the script
when dispatched to a compute node. The queuing system
identified which compute node is available to perform the work.
OUTPUT
Submitted batch job 11783863And that’s all we need to do to submit a job. Our work is done – now the scheduler takes over and tries to run the job for us.
Monitor your batch job
While the job is waiting to run, it goes into a list of jobs called
the queue. To check on our job’s status, we check the queue
using the command squeue -u $USER.
OUTPUT
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
11783909 regular example- iskander R 0:06 1 sml-n02ST is short for status and can be R (RUNNING), PD (PENDING), CA (CANCELLED), or CG (COMPLETING). If the job is stuck in pending, REASON column will reflect the reason, which can be one of the following:
- Priority: There are higher priority jobs than yours
- Resources: Job is waiting for resources
- Dependency: This job is dependent on another and it is waiting for that other job to complete
- QOSMaxCpuPerUserLimit: User has used CPUs limit of partition already
- QOSMaxMemPerUserLimit: User has used memory limit of partition already
Where’s the Output?
On the login node, this script printed output to the terminal – but
now, when the job has finished, nothing was printed to the terminal.
Cluster job output is typically redirected to a file in the directory
you launched it from. By default, the output file is called
slurm-<jobid>.out
Use ls to find and cat to read the
file.
Exercise 2: Get output of running example-job.sh in Slurm
List files in your currrent working directory and look for a file
Slurm-11783909.out, 11783909 will change
according to your job id. And cat the file to see output.
What is the hostname of your job?
Customising a Job
The job we just ran used all of the scheduler’s default options. In a real-world scenario, that’s probably not what we want. Chances are, we will need more cores, more memory, more/less time, among other special considerations. To get access to these resources we must customize our job script.
The default parameters on Milton is 2 CPU, 10MB Ram, 48-hours time-limit and runs on the regular partition
After your job has completed, you can get details of the job using
sacct command.
OUTPUT
JobID JobName NCPUS ReqMem Timelimit Partition
------------ ---------- ---------- ---------- ---------- ----------
11783909 example-j+ 2 10M 2-00:00:00 regularWe can change the resource specification of the job by two ways:
Adding extra options to the sbatch command
Modifying the submission script
BASH
#!/bin/bash
#SBATCH --job-name hello-world
#SBATCH --mem 1G
#SBATCH --cpus-per-task 1
#SBATCH --time 1:00:00
echo -n "This script is running on "
hostnameSubmit the job and monitor its status:
BASH
$ sbatch example-job.sh
Submitted batch job 11785584
$ squeue -u $USER
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
11785584 regular hello-wo iskander R 0:01 1 sml-n20Comments in shell scripts (denoted by #) are typically
ignored, but there are exceptions. Schedulers like SLURM have a special
comment used to denote special scheduler-specific options. Though these
comments differ from scheduler to scheduler, SLURM’s special comment is
#SBATCH. Anything following the #SBATCH
comment is interpreted as an instruction to the scheduler. These SBATCH
commands are also know as SBATCH directives.
Remember Slurm directives must be at the top of the script, below the “hash bang”. No command can come before them, nor in between them.
Resource Requests
One thing that is absolutely critical when working on an HPC system is specifying the resources required to run a job. This allows the scheduler to find the right time and place to schedule our job. As we have seen before, if you do not specify requirements, you will be stuck with default resources, which is probably not what you want.
The following are several key resource requests:
-
--timeor-t: Time (wall-time) required for a job to run. Thepart can be omitted. default = 48 hours on the regular queue -
--mem: Memory requested per node in MiB. Add G to specify GiB (e.g. 10G). There is also--mem-per-cpu. default = 10M -
--nodesor-N: Number of nodes your job needs to run on. default = 1 -
--cpus-per-taskor-cNumber of CPUs for each task. Use this for threads/cores in single-node jobs. -
--partitionor-p: the partition in which your job is placed. default = regular -
--ntasksor-n: Number of tasks (used for distributed processing, e.g. MPI workers). There is also--ntasks-per-node. default = 1
-
--gres: special resources such as GPUs. To specify gpus, use gpu:: , for example, gres=gpu:P100:1, and you must specify the correct queue (gpuq or gpuq_large)
Note that just requesting these resources does not make your job run faster, nor does it necessarily mean that you will consume all of these resources. It only means that these are made available to you. Your job may end up using less memory, or less time, or fewer nodes than you have requested, and it will still run. It’s best if your requests accurately reflect your job’s requirements.
In summary, the main parts of a SLURM submission script
1. #! line:
This must be the first line of your SBATCH/Slurm script.
#!/bin/bash
2. Resource Request:
This is to set the amount of resources required for the job.
BASH
#SBATCH --job-name=TestJob
#SBATCH --time=00:10:00
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=1
#SBATCH --mem=500M3. Job Steps
Specify the list of tasks to be carried out. It may include an
initial load of all the modules that the project depends on to execute.
For example, if you are working on a python project, you’d definitely
require the python module to run your code.
bash module load python echo "Start process" hostname sleep 30 python myscript.py echo "End"
All the next exercises will use scripts saved in the exercise folder
which you should have moved to your current directory.
After 1 minute the job ends and the output is similar to this
OUTPUT
This script is running on Slurmstepd: error: *** JOB 11792811 ON sml-n24 CANCELLED AT 2023-05-13T20:41:10 DUE TO TIME LIMIT ***To fix it, change the script to
BASH
#!/bin/bash
#SBATCH -t 00:01:20 # timeout in HH:MM
echo -n "This script is running on "
sleep 70 # time in seconds
hostnameTry running again.
Resource requests are typically binding. If you exceed them, your job will be killed.
The job was killed for exceeding the amount of resources it requested. Although this appears harsh, this is actually a feature. Strict adherence to resource requests allows the scheduler to find the best possible place for your jobs. Even more importantly, it ensures that another user cannot use more resources than they’ve been given. If another user messes up and accidentally attempts to use all of the cores or memory on a node, Slurm will either restrain their job to the requested resources or kill the job outright. Other jobs on the node will be unaffected. This means that one user cannot mess up the experience of others, the only jobs affected by a mistake in scheduling will be their own.
Exercise 4: Setting appropriate Slurm directives
When submitting to Slurm, you get an error
OUTPUT
sbatch: error: Batch job submission failed: Requested node configuration is not availableThis is because a GPU was requested without specifying the correct GPU partition, so the regular partition was used which has no GPUs. To fix it, change the script to
BASH
#!/bin/bash
#SBATCH -t 00:01:00
#SBATCH -p gpuq
#SBATCH --gres gpu:P100:1
#SBATCH --mem 1G
#SBATCH --cpus-per-task 1
#This is a job that needs GPUs
echo -n "This script is running on "
hostnameTry running again.
Exercise 5
Make alignment job (job3.sh) work.
Exercise 6: Run job3.sh again and monitor progress on the node .
Run job3.sh again and monitor progress on the node. You
can do this by sshing to the node and running top.
- Run the job
- Get which node it is running on from
squeue -u $USER - ssh into the node
- use
top -u $USER
We can have a live-demo on how to monitor a running job on the
compute node, using top, iotop and
nvtop for GPU nodes
Cancelling a Job
Sometimes we’ll make a mistake and need to cancel a job. This can be
done with the scancel command. Let’s submit a job and then
cancel it using its job number.
BASH
sbatch example-jobwithsleep.sh
Submitted batch job 11785772
$ squeue -u $USER
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
11785772 regular example- iskander R 0:10 1 sml-n20
$ scancel 11785772
$ squeue -u $USER
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
$We can also cancel all of our jobs at once using the -u option. This will delete all jobs for a specific user (in this case, yourself). Note that you can only delete your own jobs.
Try submitting multiple jobs and then cancelling them all.
Exercise 7: Submit multiple jobs and then cancel them all.
Check what you have in the queue
OUTPUT
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
11792908 regular job1.sh iskander R 0:13 1 sml-n23
11792909 regular job1.sh iskander R 0:13 1 sml-n23
11792906 regular job1.sh iskander R 0:16 1 sml-n23
11792907 regular job1.sh iskander R 0:16 1 sml-n23Cancel the jobs
Recheck the queue
And the queue is empty.
You can check how busy the queue is through the Milton
dashboards or by using the sinfo tool.
OUTPUT
PARTITION AVAIL TIMELIMIT NODES(A/I/O/T) NODELIST
interactive up 1-00:00:00 7/2/0/9 il-n[01-03],med-n[01-03],sml-n[01-03]
regular* up 2-00:00:00 57/26/0/83 il-n[01-20],lrg-n[02-04],med-n[02-38],sml-n[02-24]
long up 14-00:00:0 56/24/0/80 il-n[01-20],med-n[02-38],sml-n[02-24]
bigmem up 2-00:00:00 4/2/0/6 cl-n01,lrg-n[01-02],med-n[02-04]
datamover up 7-00:00:00 1/2/0/3 dm-n[01-03]
gpuq up 2-00:00:00 5/10/0/15 gpu-a30-n[01-07],gpu-a100-n[01-03],gpu-p100-n[01-05]
gpuq_interactive up 12:00:00 1/0/0/1 gpu-a10-n01Slurm Event notification
You can use --mail-type and --mail-user to
set SLURM to send you emails when certain events occurs, e.g. BEGIN,
END, FAIL, REQUEUE, ALL
Adding the above two lines to a submission script will make Slurm send me an email when my job starts running.
Slurm Output files
By default both standard output and standard error are directed to a
file of the name “slurm-%j.out”, where the “%j” is replaced with the job
id. The file will be saved in the submission directory as we saw before.
You can choose where the output files is saved and also separate
standard output from standard error using --output and
--error
-
--outputcan be used to change the standard output filename and location. -
--errorcan be used to specify where the standard output file shall be saved. If not specified, it will be directed to the standard output file.
In the file names you can use:
- %j for job id
- %N for host name
- %u for user name
- %x for job name
For example, running the following
BASH
sbatch --error=/vast/scratch/users/%u/slurm%j_%N_%x.err --output=/vast/scratch/users/%u/slurm%j_%N_%x.out job1.shwill write error to slurm12345678_sml-n01_job1.sh.err
and output to slurm12345678_sml-n01_job1.sh.out in the
directory /vast/scratch/users/<username>
i.e. the following will be created:
- a standard output file
/vast/scratch/users/iskander.j/slurm11795785_sml-n21_job1.sh.outand - an error files
/vast/scratch/users/iskander.j/slurm11795785_sml-n21_job1.sh.err.
Bonus QoS and preemption
Before we move to our next lesson, let’s breiflt talk about the bonus QoS. We have discussed before the limits of each partition. So what if you have run many jobs and hit the limit on the regular partition but when you look at the dashboards you observe that there are still free resources that can be used?
Can you make use of them as long as no one else needs them? Yes you can!
You can use --qos=bonus.
This will run your job in a preemptive mode, which means other users can terminate your job, if Slurm couldn’t find other resources for their jobs and they are using the normal QoS.
This is useful for jobs that can be resumed or restart is not an issue.
-
sbatchis used to submit the job -
squeueis used to list jobs in the Slurm queue- passing the
-u <username>option will show jobs for just that user.
- passing the
-
sacctis used to show job details -
#SBATCHdirectives are used in submission scripts to set Slurm directives - Setting up job resources is a challenge and you might not get the first time
Content from Lunch Break
Last updated on 2025-04-24 | Edit this page
Estimated time: 0 minutes
Take a 40-minutes lunch break.
Make sure you move around and look at something away from your screen to give your eyes a rest.
Content from Evaluating Jobs
Last updated on 2025-04-24 | Edit this page
Estimated time: 22 minutes
Overview
Questions
- How to evaluate a completed job?
- How to set event notification for your jobs?
Objectives
- Explain Slurm environment variables.
- Demonstrate how to evaluate jobs and make use of multiple threads options.
Evaluating your Job
After a job has completed, you will need to evaluate how efficient it was, if it ran successfully, or investigate why it failed.
The seff command provides a summary of any job.
Exercise 1: Run and evaluate job4.sh .
job4.sh is similar to job3.sh with only the bowtie2
command. Try submitting it. Is there an error? How to fix it?
And after it completed successfully, evaluate the job.
The jobs completes fast but not successfully
OUTPUT
Job ID: 11793501
Cluster: milton
User/Group: iskander.j/allstaff
State: OUT_OF_MEMORY (exit code 0)
Nodes: 1
Cores per node: 2
CPU Utilized: 00:00:01
CPU Efficiency: 50.00% of 00:00:02 core-walltime
Job Wall-clock time: 00:00:01
Memory Utilized: 0.00 MB (estimated maximum)
Memory Efficiency: 0.00% of 20.00 MB (10.00 MB/core)Also, checking output
OUTPUT
.........................<other output>
slurmstepd: error: Detected 1 oom_kill event in StepId=11793501.batch. Some of the step tasks have been OOM Killed.This shows that the job was “OOM Killed”. OOM is an abbreviation of Out Of Memory, meaning the memory requested was not enough, increase memory and try again until job finishes successfully.
Exercise 2: Run and evaluate job4.sh .
Now that the job works fine can we make it faster.
Slurm Environment Variables
Slurm passes information about the running job e.g what its working directory, or what nodes were allocated for it, to the job via environmental variables. In addition to being available to your job, these are also used by programs to set options like number of threads to run based on the cpus available.
The following is a list of commonly used variables that are set by Slurm for each job
-
$SLURM_JOBID: Job id -
$SLURM_SUBMIT_DIR: Submission directory -
$SLURM_SUBMIT_HOST: Host submitted from -
$SLURM_JOB_NODELIST: list of nodes where cores are allocated -
$SLURM_CPUS_PER_TASK: number of cores per task allocated -
$SLURM_NTASKS: number of tasks assigned to job
Exercise 3: Run job5.sh.
Can we make use on of Slurm environment variables in job4.sh?
use $SLURM_CPUS_PER_TASK with -p option
instead of setting a number.
- Use
seffto evaluate completed jobs - Slurm Environment variables are handy to use in your script
Content from Slurm Commands
Last updated on 2023-05-15 | Edit this page
Estimated time: 22 minutes
Overview
Questions
- How to use Slurm commands?
Objectives
- Explain how to use the other Slurm commands?
- Demonstrate different options for Slurm commands like
squeueandsinfo.
Slurm Commands Summary
| Command | Action |
|---|---|
sbatch <script> |
Submit a batch script |
sacct |
Display job details (accounting data) |
sacctmgr |
View account information |
squeue |
View information of jobs currently in queue |
squeue -j <jobid> |
Get specific job details, job should be in the queue |
squeue -u <userid> |
Get all queued job details for specified user |
scancel <jobid> |
Cancel job |
sinfo |
View information about nodes and partitions |
sinfo -N |
View list of nodes |
sinfo -s |
Provides nodes’ state information in each partitions |
sinfo -p <partition> |
Provides nodes’ state information in the specified partition |
scontrol show job <jobid> |
View detailed job information |
scontrol show partition <partition> |
View detailed partition information |
Provides summary information of only the specified partition
OUTPUT
PARTITION AVAIL TIMELIMIT NODES(A/I/O/T) NODELIST
gpuq up 2-00:00:00 2/10/0/12 gpu-a30-n[01-07],gpu-p100-n[01-05]Provides information of the specified node in the specified partition
OUTPUT
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
gpuq up 2-00:00:00 0 n/aThe results says that node is not available, this is because there is
no node called sml-n02 in the regular partition. To fix it,
we can either change the partition to regular or the node
to something like gpu-a30-n01
OUTPUT
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
regular* up 2-00:00:00 1 mix sml-n02OUTPUT
JOBID PARTITION NAME USER STATE TIME CPUS TIME_LIMIT NODES REASON MIN_MEMORY NODELIST PRIORITY
11774748 gpuq guppy luo.q PENDING 0:00 20 2-00:00:00 1 QOSMaxNodePerU 400G 2060
11774747 gpuq guppy luo.q PENDING 0:00 20 2-00:00:00 1 QOSMaxNodePerU 400G 2060
11774746 gpuq guppy luo.q PENDING 0:00 20 2-00:00:00 1 QOSMaxNodePerU 400G 2060
11774744 gpuq guppy luo.q RUNNING 1-05:28:48 20 2-00:00:00 1 None 400G gpu-a30-n01 1366
11774745 gpuq guppy luo.q RUNNING 1-05:41:49 20 2-00:00:00 1 None 400G gpu-a30-n03 1360
OUTPUT
NODELIST PARTITION STATE CPUS MEMORY ALLOCMEM AVAIL_FEATURES CPUS(A/I/O/T) GRES_USED
cl-n01 bigmem idle 192 3093716 0 Cooperlake,AVX512 0/192/0/192 gpu:0
gpu-a10-n01 gpuq_intera idle 48 256215 0GPU,Icelake,A10,AVX5 0/48/0/48. gpu:A10:0
gpu-a30-n01 gpuq mixed 96 511362 409600GPU,Icelake,A30,AVX5 20/76/0/96. gpu:A30:1
gpu-a30-n02 gpuq idle 96 511362 0GPU,Icelake,A30,AVX5 0/96/0/96. gpu:A30:0
gpu-a30-n03 gpuq mixed 96 511362 409600GPU,Icelake,A30,AVX5 20/76/0/96. gpu:A30:0
gpu-a30-n05 gpuq idle 96 511362 0GPU,Icelake,A30,AVX5 0/96/0/96 gpu:A30:0
gpu-a30-n06 gpuq idle 96 511362 0GPU,Icelake,A30,AVX5 0/96/0/96. gpu:A30:0
gpu-a30-n07 gpuq idle 96 511362 0GPU,Icelake,A30,AVX5 0/96/0/96. gpu:A30:0
gpu-a100-n01 gpuq_large mixed 96 1027457 819200GPU,Icelake,A100,AVX 2/94/0/96. gpu:A100:1
gpu-a100-n02 gpuq_large mixed 96 1027457 819200GPU,Icelake,A100,AVX 2/94/0/96. gpu:A100:1
gpu-a100-n03 gpuq_large mixed 96 1027457 819200GPU,Icelake,A100,AVX 2/94/0/96. gpu:A100:1- Slurm commands are handy to view information about queued jobs, nodes and partitions
- You will commonly use
sbatch,squeue,salloc,sinfoandsacct
Content from Interactive Slurm Jobs
Last updated on 2025-04-23 | Edit this page
Estimated time: 10 minutes
Overview
Questions
- How to start and exit an interactive Slurm job?
Objectives
- Explain how to use
sallocto run interactive jobs
Interactive jobs
Up to this point, we’ve focused on running jobs in batch mode. There are frequently tasks that need to be done interactively. Creating an entire job script might be overkill, but the amount of resources required is too much for a login node to handle. To solve this, Slurm provides the ability to start an interactive session.
Interactive sessions are commonly used for:
- Data management, eg. organising files, truncation and recall of files, downloading datasets.
- Software/workflow preparation/testing, eg. developing/debugging scripts, downloading/building software.
- Interactive data analysis.
- Rapid analysis cycles.
- Running n application with a GUI.
On Milton, you can easily start an interactive job with
salloc.

You will be presented with a bash prompt. Note that the prompt will
change to reflect your new location (sml-n02 in the
example), which is the compute node we are logged onto. You can also
verify this with hostname.
Remember that, you may have to wait for resources, depending on the status of the queue you are requesting. We have designed the interactive partition to provide high availability, but only one job per user.
The interactive job will be cancelled and removed from the queue, if
your terminal session is terminated or closed, and/or internet
connection is lost (connection with the slurm node lost). It is
recommended to use screen or tmux
When you have finished your task, please remember to close the
session using exit or Ctrl-D.
You can also cancel the session using scancel.
If you need more resources you can run interactive sessions in the other partitions.
These instructions are specific Milton!
salloc is setup slightly differently to its default
behaviour. Not all HPC facilities have Slurm to start interactive jobs
like in Milton! Be aware of this when using the command at other
facilities.
Creating remote graphics
To see graphical output inside your jobs, you need to use X11
forwarding. To connect with this feature enabled, use the
-Y option when you login to the login nodes or
slurm-login.
ssh -Y slurm-loginTo use it in an interactive session add it to --x11 to
your salloc command
OUTPUT
salloc: Pending job allocation 11803274
salloc: job 11803274 queued and waiting for resources
salloc: job 11803274 has been allocated resources
salloc: Granted job allocation 11803274
salloc: Nodes sml-n03 are ready for jobOUTPUT
Loading Relion 4.0.1 using CUDA 12.1
Using MotionCor2 1.6.4 at /stornext/System/data/software/rhel/9/base/structbio/motioncor2/1.6.4_CUDA12.1/bin/motioncor2
Using CTFFIND 4.1.14 at /stornext/System/data/software/rhel/9/base/structbio/ctffind/4.1.14/bin/ctffind
WARNING: verify that the area where Relion will be used
is not over its storage quota. If Relion is unable to write
files this might cause severe corruption in the Relion
pipeline star files.
Loading relion/4.0.1_CUDA12.1
Loading requirement: CUDA/12.1 openmpi/4.1.6
We will now have a live demo for more interactive options on Milton.
- Use
sallocto start a new interactive Slurm job on Milton. - Use
--x11withsallocto run remote graphics in your interactive job.